ЗжзгПЫТЁММЪѕЭЈГЃЬижИЛљвђПЫТЁЃЈgene cloningЃЉЛђDNAжизщММЪѕЃЈrecombinant DNA technologyЃЉЁЃЛљвђПЫТЁжївЊАќРЈЃКЂйСЌНгЭтдДЛљвђКЭПЫТЁдиЬхЃЌЙЙНЈжизщDNAЗжзгЃЌЂкНЋжизщDNAЗжзгзЊШыЪмЬхЯИАћЃЌЪЙЭтдДЛљвђЫцЪмЬхЯИАћЗжСбЖјЕУвдИДжЦЁЂЗБжГЁЃ
ЁЁЁЁвЛИіЕфаЭЕФЛљвђПЫТЁЪЕбщЃЌжївЊгавдЯТВйзїКЭНсЙћЃК
ЁЁЁЁЃЈ1ЃЉАќРЈгаФПЕФЛљвђдкФкЕФDNAЦЌЖЯВхШыСэвЛИіDNAЗжзгЃЈПЫТЁдиЬхЃЌЭЈГЃЪЧЛЗзДЕФЃЉЃЌаЮГЩжизщDNAЗжзгЁЃ
ЁЁЁЁЃЈ2ЃЉжизщDNAЗжзгЭЈЙ§зЊЛЏЛђЦфЫћРрЫЦЕФЗНЗЈБЛЕМШыЪмЬхЯИАћЁЃДѓГІИЫОњЪЧЪЙгУНЯЖрЕФЪмЬхЯИАћЁЃ
ЁЁЁЁЃЈ3ЃЉдкЪмЬхЯИАћжаЃЌПЫТЁдиЬхжИЕМжизщDNAЗжзгИДжЦЃЌВњЩњаэЖрЭъШЋЯрЭЌЕФПНБДЁЃ
ЁЁЁЁЃЈ4ЃЉЕБЪмЬхЯИАћЗжСбЪБЃЌжизщDNAЗжзгЕФПНБДНјШызгЯИАћЃЌПЫТЁдиЬхЕФИДжЦНЋдкзгЯИАћжаМЬајЁЃ
ЁЁЁЁЃЈ5ЃЉДѓСПЗжСбЕФЪмЬхЯИАћаЮГЩПЫТЁЃКвЛИіЯИАћШКЬхЃЌЦфжаУПИіЯИАћЖМКЌгааэЖржизщDNAЗжзгЕФПНБДЁЃ
ЁЁЁЁЯдЖјвзМћЃЌЛљвђПЫТЁЪЧвЛИіБШНЯжБЙлЖјМђЕЅЕФВйзїГЬађЁЃЫќжЎЫљвдОпгаЗЧГЃживЊЕФЩњЮябЇвтвхЃЌЪЧвђЮЊетвЛММЪѕПЩвдЮЊЮвУЧЬсЙЉвЛИіДПДтЕФЛљвђБъБОЁЃЭЈГЃЃЌвЛИіЛљвђзмЪЧКЭЯИАћРяЦфЫћЛљвђЭЌдкЁЃЛљвђПЫТЁММЪѕЕЎЩњжЎЧАЃЌЮвУЧИљБОЮоЗЈДПЛЏЕЅИіЛљвђЃЌетвтЮЖзХЮвУЧжЛФмЖдЛљвђШКЁЂЖјВЛЪЧЬиЖЈЛљвђЕФНсЙЙгыЙІФмНјаабаОПКЭПЊЗЂРћгУЁЃ
ЁЁЁЁЙЙНЈжизщDNAЗжзгЪЧЛљвђПЫТЁЪЕбщЕФЕквЛВНЃЌврМДЃЌАбЛЗзДЕФдиЬхдкжИЖЈВПЮЛЧаЖЯЃЌШЛКѓАбКЌФПЕФЛљвђЕФDNAЗжзгВхШыЦфжаЃЌдйНЋСНепСЌНгЦ№РДЁЃетвЛЙ§ГЬашвЊСНжжDNAВйзїУИЃКЯожЦадФкЧаУИЃЈrestriction endonucleasesЃЉКЭСЌНгУИЃЈligasesЃЉЁЃ
ЁЁЁЁЯожЦадФкЧаУИФмЙЛЪЖБ№DNAЗжзгЩЯЕФЬиЖЈКЫмеЫсађСаЃЌВЂдкИУДІЬивьадЧаЖЯDNAЗжзгЁЃР§ШчЃЌPvuIЃЈЯИОњProteus vulgarisЗжРыЃЉжЛЪЖБ№КЭЧаЖЯ6КЫмеЫсађСаCGATCGЃЛДгЯрЭЌЯИОњЗжРыЕФPvuIIЃЌШДжЛЪЖБ№ВЂЧаЖЯCAGCTGЁЃаэЖрЯожЦадФкЧаУИЕФЪЖБ№ЮЛЕуЪЧ6ИіКЫмеЫсЃЌЕЋЪЧЃЌвВгаЪЖБ№4ИіЛђ5ИіЁЂЩѕжС8ИіКЫмеЫсЫГађЕФЯожЦадФкЧаУИЁЃДЫЭтЃЌгааЉЯожЦадФкЧаУИЕФЪЖБ№ЫГађПЩФмВЛЪЧЮЈвЛЕФЃЌР§ШчЃЌHinfIПЩвдЪЖБ№ВЂЧаЖЯGAATCЁЂGATTCЃЌGAGTCКЭGACTCЁЃвђДЫЃЌЭЈГЃвВНЋHinfIЕФЪЖБ№ЮЛЕуМЧЮЊGANTCЃЌNДњБэAЁЂTЁЂGКЭCжаЕФШЮвтвЛжжКЫмеЫсЁЃ
ЁЁЁЁОЯожЦадФкЧаУИДІРэКѓЕФDNAЗжзгЖЯЖЫгаСНжжЃКЦНЖЫКЭеГЖЫЃЌЫќУЧЕФаджЪЖдЛљвђПЫТЁЕФЪЕбщЩшМЦгаживЊгАЯьЁЃЦфжаЃЌОпгаВЛЭЌЪЖБ№ЮЛЕуЕФЯожЦадФкЧаУИПЩвдВњЩњЯрЭЌЕФеГЖЫЁЃР§ШчЃЌBglIIЃЈAGATCTЃЉКЭBamHIЃЈGGATCCЃЉВњЩњгыSau3AЯрЭЌЕФGATCеГЖЫЁЃЯдШЛЃЌОЩЯЪіШ§жжУИДІРэЕФDNAЗжзгЦЌЖЯжЎМфОљПЩвддкЯргІЕФЖЯЖЫаЮГЩЛЅВЙЫЋСДЁЃ
ЁЁЁЁDNAЗжзгЦЌЖЯЭЈЙ§еГЖЫаЮГЩЕФМюЛљЛЅВЙВЂВЛФмЪЙжЎЯрЛЅСЌНгЃЌКѓвЛЙ§ГЬашвЊСЌНгУИЕФДпЛЏзїгУЁЃЫљгаЩњЮяЯИАћжаЖМВњЩњСЌНгУИЃЌЕЋЪЧЃЌЛљвђПЫТЁжазюГЃгУЕФЪЧT4ЪЩОњЬхЕФСЌНгУИЁЃСЌНгУИДпЛЏЯрСкКЫмеЫсжЎМфаЮГЩСзЫсЖўѕЅМќЁЃгЩгкЦНЖЫВЛФмЪЙDNAЦЌЖЯБЃГжЯрЛЅНгНќЕФЮЛжУЃЌвђЖјЃЌКЭеГЖЫЯрБШЃЌСЌНгУИЖдЦНЖЫDNAЗжзгжЎМфСЌНгЗДгІЕФДпЛЏаЇТЪНЯВюЁЃ
ЁЁЁЁдиЬхЪЧПЫТЁЛљвђЕФЙиМќзщЗжЃЌдиЬхЪЙжизщDNAЗжзгФмЙЛдкЪмЬхЯИАћжаИДжЦЁЃжЪСЃКЭЪЩОњЬхЪЧСНжжЬьШЛЕФDNAдиЬхЁЃФПЧАЃЌФмдкВЛЭЌЪмЬхЯИАћжаЪЙгУЕФдиЬхгаЪ§АйжжЃЌЦфжаЃЌПЩвддкДѓГІИЫОњжаЪЙгУЕФдиЬхЪ§ФПзюЖрЁЃ
ЁЁЁЁжЪСЃpBR322ЪЧвЛжжЕфаЭЕФДѓГІИЫОњПЫТЁдиЬхЃЌЫќШЋГЄНіЮЊ4.3kbЃЈЭЈГЃЃЌЮвУЧКмФбЭъећЕиЗжРыКЭДПЛЏГЄЖШГЌЙ§50kbЕФDNAДѓЗжзгЃЉЁЃpBR322ДјгаСНжжПЙЩњЫиПЙадЛљвђЃКb -ФкѕЃАЗУИЛљвђКЭЫФЛЗЫиПЙадЛљвђЃЌЧАепаоЪЮВЂЯћГ§АБмаЧрУЙЫиЖдДѓГІИЫОњЕФЖОадЁЃЭЈГЃЃЌФПЕФЛљвђВхШыдиЬхжЪСЃНЋЦЦЛЕЫФЛЗЫиПЙадЙІФмЁЃвђДЫЃЌЪЙгУКЌгаАБмаЧрУЙЫиКЭЫФЛЗЫиЕФХрбјЛљЃЌЮвУЧПЩвдМјБ№ДѓГІИЫОњЕФзЊЛЏЯИАћЃКДјгажизщжЪСЃЕФзЊЛЏЯИАћжЛФмдкКЌАБмаЧрУЙЫиЁЂВЛКЌЫФЛЗЫиЕФХрбјЛљЩЯЩњГЄЃЛСэвЛЗНУцЃЌдЪмЬхЯИАћВЛФмдкКЌгаАБмаЧрУЙЫиКЭЫФЛЗЫиЕФХрбјЛљЩЯЩњГЄЃЛЖјгадиЬхжЪСЃЕЋУЛгаФПЕФЛљвђЕФзЊЛЏЯИАћФмдкКЌгаАБмаЧрУЙЫиКЭЫФЛЗЫиЕФХрбјЛљЩЯЩњГЄЁЃСэЭтЃЌpBR322ЪЧвЛжжЫЩГкаЭжЪСЃЃЌдкХрбјвКжаМгШыТШУЙЫиПЩвдЪЙзЊЛЏЯИАћжаЕФжЪСЃПНБДЪ§гЩЭЈГЃЕФ15ИідіжС1000-3000ИіЃЌДЫМфЃЌДѓГІИЫОњЕФШОЩЋЬхВЂВЛИДжЦЁЃ
ЁЁЁЁЪЕМЪЩЯЃЌЯждкОГЃЪЙгУЕФаэЖржЪСЃдиЬхВЛЭЌгкpBR322ЃЌГ§ПЙЩњЫиПЙадЛљвђжЎЭтЃЌетаЉжЪСЃжаЕФЦфЫћЛљвђвВПЩвдзїЮЊбЁдёЛљвђЁЃР§ШчЃЌpUC8ДјгаАБмаЧрУЙЫиПЙадЛљвђКЭLacZ/ЛљвђЁЃгЩгкФПЕФЛљвђЕФВхШыВПЮЛЮЛгкLacZ/ЛљвђжЎФкЃЌЫљвдЃЌечБ№зЊЛЏЯИАћЕФВйзїБфЕУИќМгжБЙлКЭМђЕЅЁЃжЪСЃФмЪЙзЊЛЏЯИАћдкКЌгаАБмаЧрУЙЫиЕФХрбјЛљЩЯЩњГЄЃЌВЂЧвЃЌШчЙћЭЌЪБЬэМгLacZ/ЛљвђБэДягеЕМЮяжЪIPTGКЭLacZ/УИЃЈb-АыШщЬЧмеУИЃЉЕФЕзЮяX-galЃЌФЧУДЃЌДјгаФПЕФЛљвђЕФзЊЛЏЯИАћОњТфГЪЯжРЖЩЋЃЌВЛКЌФПЕФЛљвђЕФзЊЛЏЯИАћОњТфГЪЯжАзЩЋЁЃ
ЁЁЁЁдкЯИОњжаЃЌЪЩОњЬхдиЬхЪЧСэЭтвЛРрГЃгУЕФПЫТЁдиЬхЁЃКЭжЪСЃВЛЭЌЕФЪЧЃЌЪЩОњЬхдиЬхЭЈЙ§ИаШОЙ§ГЬМДзЊЕМНјШыЫожїДѓГІИЫОњЯИАћЁЃЭЈГЃЃЌзїЮЊПЫТЁдиЬхЕФЪЩОњЬхЃЌЖМОЙ§вЛЖЈЕФЭЛБфКЭШБЪЇДІРэЁЃвђДЫЃЌетРрЪЩОњЬхНјШыДѓГІИЫОњЯИАћжЎКѓЃЌВЂВЛЯёвЛАуЪЩОњЬхФЧбљдкЫожїШОЩЋЬхЩЯећКЯЃЌЖјЪЧжБНгНјШыСбНтжмЦкЃКДѓСПИДжЦЪЩОњЬхЁЂСбНтЫожїЯИАћЃЌзюжедкХрбјЛљЩЯаЮГЩКЌгаДѓСПЪЩОњЬхПНБДЕФЪЩОњАпЁЃ
ЁЁЁЁЩИбЁДјгаФПЕФЛљвђЕФЪЩОњЬхЕФЗНЗЈЖржжЖрбљЃЌР§ШчЃЌЪЙгУгаLacZ/ЛљвђЕФЪЩОњЬхдиЬхЪБЃЌПЩвдЭЈЙ§X-galХрбјЛљЩЯаЮГЩЪЩОњАпЕФбеЩЋЃЌЧјБ№ДјгаФПЕФЛљвђЕФжизщЪЩОњЬхЃЈжизщзгЃЉКЭУЛгаФПЕФЛљвђЕФдиЬхЁЃгаЪБЃЌвВПЩвдМђЕЅЕиЭЈЙ§зЊЕМЧАКѓЫљаЮГЩЕФЪЩОњАпаЮЬЌМјБ№жизщзгЁЃ
ЁЁЁЁКЭжЪСЃдиЬхЯрБШЃЌЪЩОњЬхдиЬхФмЙЛПЫТЁИќГЄЕФDNAЦЌЖЯЁЃР§ШчЃЌpBR322МАpUC8ЕФжЪСЃжаПЩвдВхШызюГЄ8kbЕФDNAЦЌЖЯЃЌдиЬхЕШЪЩОњЬхдђФмПЫТЁГЄДя25kbЕФDNAЦЌЖЯЁЃ
ЁЁЁЁЭЈГЃЃЌДѓГІИЫОњМАЦфжЪСЃЛђЪЩОњЬхдиЬхПЩвдГфЗжТњзуЗжРыКЭДПЛЏФГаЉЪЕбщгУЛљвђЕФФПЕФЁЃЕЋЪЧЃЌЮвУЧгаЪБашвЊгУецКЫЩњЮяЯИАћЖјВЛЪЧДѓГІИЫОњЯИАћзїЮЊЪмЬхЃЌР§ШчЃЌРћгУЛљвђПЫТЁПижЦКЭДйНјживЊДњаЛВњЮяЃЈвШЕКЫиЕШЃЉЕФКЯГЩЁЂИФБфЪмЬхЩњЮяЕФЬиЖЈадзДЃЈНЋПЙГцЬиадЕМШыСИЪГзїЮяЕШЃЉЃЌЕШЕШЁЃетЪБЃЌЮвУЧБиаыбЁдёЪЪКЯгкецКЫЯИАћЕФПЫТЁдиЬхЁЃ
ЁЁЁЁНЭФИЪЧЛљвђПЫТЁЪЕбщжаГЃгУЕФецКЫЩњЮяЪмЬхЯИАћЃЌХрбјНЭФИОњКЭХрбјДѓГІИЫОњвЛбљЗНБуЁЃНЭФИПЫТЁдиЬхЕФжжРрвВКмЖрЁЃЦфжаЃЌгЮРыаЭжЪСЃYEpsЃЈyeast episomal plasmidsЃЉЁЂећКЯаЭдиЬхYIpsЃЈIntegrative yeast vectorsЃЉКЭШЫЙЄШОЩЋЬхYACsЃЈyeast artificial chromosomesЃЉЪЧШ§жжзюОпДњБэадЕФНЭФИПЫТЁдиЬхЁЃYEpsЪЧвЛжжКБМћЕФецКЫЯИАћжЪСЃЃЌДѓаЁ2mmЁЂГЄдМ6kbЁЃYEpsдкЯИАћФкЕФПНБДЪ§ЮЊ70-200ИіЁЃYEpsЕФаджЪКЭЯИОњжЪСЃдиЬхЗЧГЃЯрЫЦЃЌЮЈвЛВЛЭЌЕФЪЧзЊЛЏЯИАћЕФЩИбЁЗНЗЈЁЃЪЙгУYEpsЪБЃЌжївЊЭЈЙ§ЪмЬхЯИАћгЊбјвЊЧѓЕФБфЛЏМјБ№зЊЛЏЯИАћгыЪмЬхЯИАћЁЃгЩгкРћгУYEpsПЫТЁЕФЛљвђШнвздкЯИАћМЬДњЙ§ГЬжаЖЊЪЇЃЌвђЖјЃЌШЫУЧГЃгУYIpsЬцДњYEpsЁЃВЛЙ§ЃЌзїЮЊНЭФИОњЕФПЫТЁдиЬхЃЌYIpsЕФзЊЛЏЦЕТЪКмЕЭЁЃСэвЛЗНУцЃЌЕфаЭЕФYACsАќРЈвЛИізХЫПЕуЁЂСНИіЖЫСЃЁЂвЛИіИДжЦЦ№ЕуКЭМИИібЁдёБъМЧЛљвђЃЌЪЧвЛИіЮЂаЭШОЩЋЬхЁЃYACsжївЊгУгкПЫТЁГЄЛљвђЛђАќРЈЪ§ИіЛљвђађСаЕФЛљвђзщDNAЦЌЖЯЁЃаэЖрживЊЕФЖЏЮяЛљвђЭљЭљКЌгаЖрИіФкКЌзгЁЂеМОнЯрЕБГЄЕФDNAЧјгђЃЌЖјЪЙгУЦеЭЈдиЬхЭЈГЃФбвдЛёЕУЭъећЕФЛљвђађСаПЫТЁЁЃ
ЁЁЁЁдкФГаЉЬиЪтЕФЧщаЮжаЃЌЮвУЧЛЙашвЊбЁгУЖЏЮяЛђжВЮяЯИАћзїЮЊПЫТЁЕФЪмЬхЯИАћЁЃР§ШчЃЌАбПЫТЁЕФЛљвђЕМШыСИЪГзїЮявдИФЩЦЦфгЊбјжЪСПЕШЁЃГЃгУЕФжВЮяПЫТЁдиЬхжївЊЪЧTiжЪСЃМАЦфбмЩњЮяЃЛГЃгУЕФВИШщЖЏЮяПЫТЁдиЬхжївЊЪЧвЛаЉгЩДѓГІИЫОњжЪСЃЛђВИШщРрВЁЖОИФНЈЕФдиЬхЁЃ
ЁЁЁЁЛљвђЮФПтЃЈgenomic libraryЃЉЪЧвЛЬзАќКЌЬиЖЈЩњЮяЬхЫљгаЛљвђЕФDNAађСаЃЌЦфжаЃЌВЛЭЌЕФDNAађСаЦЌЖЮЗжБ№БЛПЫТЁдкЪЪЕБЕФдиЬхЩЯЁЃР§ШчЃЌШЫРрЛљвђЮФПтЪЧвЛШКДјгаШЫРрЛљвђПЫТЁЕФДѓГІИЫОњЯИАћЃЌЮвУЧПЩвдДгетИіЮФПтжаЩИбЁЁЂМјЖЈКЭбаОПШЮКЮШЫРрЛљвђЁЃЛљвђЮФПтАќРЈгЩЛљвђзщDNAЙЙГЩЕФЛљвђзщЮФПтКЭгЩгыmRNAЛЅВЙЕФDNAЙЙГЩЕФcDNAЮФПтЁЃcDNAЮФПтВЛКЌЗЧзЊТМЕФЛљвђзщађСаЃЈжиИДађСаЕШЃЉЁЃДгЛљвђзщЮФПтжаЩИбЁКЭМјЖЈФПЕФЛљвђжївЊЗНЗЈЪЧРћгУИїжжЗжзгЬНеыЪжЖЮКЭDNAВрађвЧЁЃ
ЁЁЁЁЙЙНЈЛљвђЮФПтЕФЛљБОЗНЗЈЪЧ:ЃЈ1ЃЉНЋЬиЖЈЩњЮяЬхЕФЛљвђзщDNAЛђЛЅВЙDNAЗжНтГЩЪЪЕБГЄЖШЕФDNAЦЌЖЮЃЌШЛКѓЗжБ№гыПЫТЁдиЬхСЌНгЃЛ(2)ЭЈЙ§зЊЛЏЛђзЊЕМЕФЗНЗЈНЋДјгаВЛЭЌDNAЦЌЖЮЕФжизщDNAЗжзгЕМШыЪмЬхЯИАћЃЌЛёЕУвЛЬзАќКЌЬиЖЈЩњЮяЬхЫљгаDNAађСаЕФПЫТЁЁЃГЩЙІЙЙНЈЛљвђЮФПтЕФЙиМќЪЧбЁдёКЯЪЪЕФДПЛЏЁЂЧаЖЯDNAЕФЗНЗЈКЭПЫТЁдиЬхЃЌЪЙЫљЛёЕУЕФвЛЬзDNAађСаПЫТЁОпгаДњБэадЁЂМДВЛЖЬШБШЮКЮDNAЦЌЖЮЁЃР§ШчЃЌдкЙЙНЈЛљвђзщЮФПтЕФЙ§ГЬжаЃЌШчЙћФГвЛЖЮЛљвђзщDNAађСаУЛФмБЛПЫТЁЃЌФЧУДЃЌИУЛљвђзщЮФПтБуВЛОпгаДњБэадЁЃЯрЫЦЕиЃЌШчЙћЫљНЈЮФПтжаУЛгазуЙЛЪ§СПЕФПЫТЁЃЌФЧУДЃЌПЯЖЈЛсгаФГаЉЛљвђШБЪЇЁЃЕБШЛЃЌвЛИіЭъећЕФcDNAЮФПтвВжЛАќРЈФЧаЉгыmRNAЛЅВЙЕФDNAађСаЃЌШБЗІВЛзЊТМЕФDNAађСаЁЃ
ЁЁЁЁЗжРыКЭДПЛЏецКЫЩњЮяЛљвђзщDNAЪБЃЌЭЈГЃВЩгУЕААзУИЗжНтКЭЯрГщЬсЕФЗНЗЈГ§ЕєЕААзжЪМАжЌРрЕШЦфЫћДѓЗжзгЁЃЛљвђзщDNAЦЌЖЮЛЏдђжївЊВЩгУЮяРэМєЧаЗЈКЭЯожЦадФкЧаУИЗЈЁЃЦфжаЃЌгУНСАшМАГЌЩљВЈЕШЮяРэМєЧаЗЈДІРэЛљвђзщDNAКѓЃЌПЩЛёЕУДѓСПНЯЖЬЕФDNAЫцЛњЖЯЦЌЁЃСэвЛЗНУцЃЌгЩгкИїжжЪЖБ№ЮЛЕудкЛљвђзщDNAЩЯЪЧЗЧЫцЛњЗжВМЕФЃЌЪЙгУВЛЭЌЕФЯожЦадФкЧаУИЃЌПЩвдЛёЕУОпгаВЛЭЌГЄЖШЗжВМЬиеїЕФDNAЦЌЖЮЁЃГЃгУЕФЯожЦадФкЧаУИгаSau3AЕШЁЃ
ЁЁЁЁЙЙНЈЛљвђЮФПтжаГЃгУЕФдиЬхгажЪСЃЁЂЪЩОњЬхЁЂеГСЃЃЈcosmidЃЉвдМАYACЁЃетаЉдиЬхПЩвдПЫТЁЕФDNAЦЌЖЮГЄЖШЩЯЯоЗжБ№дМЮЊ10ЁЂ23ЁЂ45КЭ1000kbЁЃбЁдёдиЬхЕФжївЊВЮЪ§ЪЧЛљвђзщДѓаЁЃЌМДЛљвђзщDNAађСаЕФГЄЖЬЁЃР§ШчЃЌЙЙНЈДѓГІИЫОњЃЈ4.6´ 106kbЃЉЕШЛљвђзщНЯаЁЩњЮяЕФЛљвђзщЮФПтЪБЃЌВЩгУжЪСЃзїЮЊдиЬхБуПЩЕУЕНТњвтЕФНсЙћЃКАДУПИіDNAЦЌЖЮЦНОљГЄ5kbМЦЫуЃЌвЛИіАќРЈ5000ИіDNAЦЌЖЮПЫТЁЕФЛљвђЮФПтОЭФмЙЛДњБэвЛИіЭъећЕФДѓГІИЫОњЛљвђзщађСаЁЃЙЙНЈНЯДѓЛљвђзщЕФЮФПтЪБЃЌЪЩОњЬхЁЂеГСЃвдМАYACГЃБЛбЁзїПЫТЁдиЬхЁЃЦфжаЃЌEMBL3КЭlDASHЕШЪЩОњЬхЕФбмЩњЮяЪЧЙЙНЈЛљвђзщЮФПтжаЪЙгУзюЖрЕФдиЬхЁЃ
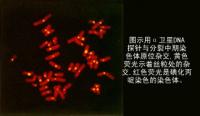
ЁЁЁЁФПЧАЃЌгаКмЖрЗНЗЈФмЙЛАяжњЮвУЧДгЛљвђЮФПтЕФжкЖрПЫТЁжаЩИбЁКЭМјЖЈДјгаЬиЖЈЛљвђЕФПЫТЁЃЌетаЉЗНЗЈДѓЖрЪЧвддгНЛЬНВщММЪѕЃЈhybridization probingЃЉЮЊЛљДЁЕФЁЃдгНЛЬНВтЪЧвЛжжРћгУФмКЭФПЕФЛљвђађСаЛЅВЙЕФDNAЛђRNAЦЌЖЮЮЊЬНеыЃЌЭЈЙ§ЗжзгдгНЛЕФЪжЖЮевГіДјгаФПЕФЛљвђЕФDNAЦЌЖЮЕФЪЕбщЗНЗЈЁЃ
ЁЁЁЁЭЈГЃЃЌЮЊСЫДгЛљвђЮФПтжаЩИбЁГіДјгаФПЕФЛљвђЕФПЫТЁЃЌЪзЯШЃЌашвЊНЋКЌгаЛљвђзщDNAЛђcDNAПЫТЁЕФОњТфЛђЪЩОњАпзЊвЦЕНЯѕЫсЯЫЮЌФЄЛђФсСњФЄЕШжЇГХЮяЩЯЁЃНјвЛВНЃЌГ§ШЅDNAвдЭтЕФЦфЫћдгЮяЃЌЭЌЪБЪЙDNAЗжзгБфадЃЈЫЋСДБфЮЊЕЅСДЃЉВЂЙЬЖЈдкжЇГХФЄЩЯЁЃзюКѓЃЌБъМЧФтЪЙгУЕФЬНеыЃЌВЂЪЙЬНеыгыжЇГХФЄЩЯЕФЕЅСДDNAЗжзгдгНЛЁЃЭЈЙ§МьВтдгНЛФЄЩЯЕФЬНеыаХКХЃЌЮвУЧПЩвдШЗЖЈДјгаФПЕФЛљвђЕФЯИОњЛђЪЩОњЬхЕФЮЛжУЃЌзюжебЁГіЯргІЕФЛљвђПЫТЁЁЃ
ЁЁЁЁзїЮЊЬНеыЕФDNAЛђRNAЗжзгДѓЖрЪЧИљОнвбжЊЕФгаЙиФПЕФЛљвђЕФФГаЉаХЯЂЃЈВПЗжDNAађСаЛђЕААзжЪВњЮяЕШЃЉЛЏбЇКЯГЩЕФЙбКЫмеЫсЁЃСэЭтЃЌБъМЧЬНеыЕФЗНЗЈвВКмЖрЃЌР§ШчЃЌЗХЩфаддЊЫиБъМЧЁЂгЋЙтЩЋЫиБъМЧвдМАУИБъМЧЕШЕШЁЃ
ЁЁЁЁВтЖЈDNAађСаЪЧОіЖЈЛљвђОЋШЗНсЙЙЕФЮЈвЛЗНЗЈЁЃDNAВтађЗЈжївЊгаСДФЉЖЫжежЙЗЈЃЈchain termination methodЃЉКЭЛЏбЇНЕНтЗЈЃЈchemical degradation methodЃЉСНРрЁЃЦфжаЃЌСДФЉЖЫжежЙЗЈФПЧАЪЙгУЕУзюЮЊЦеБщЁЃ
ЁЁЁЁгЩгкDNAВтађвЧвЛДЮжЛФмШЗЖЈГЄ500-1000bpЕФКЫмеЫсЫГађЃЌвђДЫЃЌЭЈГЃашвЊдкВтађжЎЧАЃЌЖдФтгУгкађСаЗжЮіЕФЛљвђПЫТЁНјаабЧПЫТЁжЦБИ(subcloning)КЭЯожЦадФкЧаУИЭМЦзЛцжЦЙЄзїЃКАбДгЛљвђЮФПтжаЗжРыЕФДјгаФПЕФЛљвђЕФDNAЦЌЖЮЗжГЩШєИЩИіаЁЦЌЖЮЃЌЗжБ№ПЫТЁКѓдйааВтађЃЛИљОнЯожЦадФкЧаУИЭМЦзШЗЖЈИїИібЧПЫТЁDNAЦЌЖЮжЎМфЕФЙиЯЕЃЌзюжеЛёЕУЭъећЕФЛљвђвЛМЖНсЙЙаХЯЂЁЃ
ЁЁЁЁЙњМЪDNAЪ§ОнПтЪМНЈгк20ФъЧАЃЌжївЊИКд№ЪеМЏЁЂећРэКЭНЛСїИїжжвбжЊDNAађСаЁЃНќФъРДЃЌЬиБ№ЪЧВЁЖОЁЂЯИОњЁЂРЅГцвдМАШЫЕШЖржжЩњЮяЕФЛљвђзщМЦЛЎЪЕЪЉвдРДЃЌДѓСПЕФDNAађСаЪ§Оне§вдЧАЫљЮДгаЕФЫйЖШВЛЖЯЛ§РлКЭдіЖрЁЃ
ФПЧАЃЌЙњМЪDNAЪ§ОнПтжївЊАќРЈгЩХЗжоЩњЮяаХЯЂбаОПЫљЃЈEBIЃКEuropean Bioinformatics InstituteЃЌгЂЙњНЃЧХЃЉЁЂУРЙњЙњСЂЩњЮяММЪѕаХЯЂжааФЃЈNCBIЃКNational Center for Biotechnology InformationЃЌУРЙњТэРяРМЃЉКЭШеБОЙњСЂвХДЋбЇбаОПЫљЃЈNIGЃКNational Institute of GeneticsЃЌШеБООВИдЃЉЗжБ№дЫгЊЕФEMBLЪ§ОнПтЁЂGenBankЪ§ОнПтКЭDDBJЪ§ОнПтзщГЩЁЃЫќУЧЙВЭЌжЦЖЈКЭВЩгУЯрЭЌЕФЪ§ОнПтЙмРэГЬађЃЌЗжБ№ЪеМЏЁЂећРэВЂЫцЪБНЛЛЛзюаТDNAађСааХЯЂЃЌЖЈЦкЙЋВМетаЉаХЯЂЁЃДЫЭтЃЌЫљгаЩњЮябЇЙњМЪШЈЭўадбЇЪѕПЏЮяЖМвЊЧѓЭЖИхепЪТЯШдкЙњМЪDNAЪ§ОнПтЕЧМЧФтЗЂБэЕФDNAЁЂRNAЛђЕААзжЪАБЛљЫсађСаЃЌОн1999Фъ3дТDDBJЕФЭГМЦЪ§ОнЃЈБэ5-1ЃЉЃЌЙњМЪDNAЪ§ОнПтМЭТМЕФDNAЪ§ОнзмСПвбгЩ1967ФъЕФ121ИіМюЛљЖддОЩ§ЮЊ1999ФъЕФ23вкИіМюЛљЖдЁЃ
Бэ5-1ЙњМЪDNAЪ§ОнПтЃЈ1999Фъ3дТЃЉађСаЗжРрЭГМЦ
|
ађСаЗжРр
|
ађСаЪ§ФП
|
МюЛљзмЪ§
|
|
ШЫРр
|
91,121
|
358,634,878
|
|
СщГЄРрЃЈШЫРрГ§ЭтЃЉ
|
4,977
|
3,800,669
|
|
ФіГнРр
|
45,407
|
64,541,563
|
|
ВИШщРрЃЈСщГЄРрЁЂФіГнРрГ§ЭтЃЉ
|
17,687
|
16,485,760
|
|
МЙзЕЖЏЮяЃЈСщГЄРрЁЂФіГнРрКЭВИШщРрГ§ЭтЃЉ
|
26,047
|
25,252,856
|
|
ЮоМЙзЕЖЏЮя
|
41,925
|
158.325,369
|
|
жВЮя
|
68,570
|
155,968,956
|
|
ЯИОњ
|
54,199
|
133,124,032
|
|
ЪЩОњЬх
|
1,394
|
3,033,907
|
|
ВЁЖО
|
65,827
|
59,257,968
|
|
ESTЃЈExpressed Sequence TagЃЉ
|
2,167,017
|
835,111,766
|
|
STSЃЈSequence-Tagged SiteЃЉ
|
64,115
|
22,573,045
|
|
RNA
|
4,883
|
2,480,449
|
|
зЈРћЪ§Он
|
134,612
|
42,349,047
|
|
ЦфЫћ
|
523,846
|
494,321,686
|
|
КЯМЦ
|
3,311,627
|
2,375,261,951
|
ЁЁЁЁАДееЩњЮяНјЛЏЕФЙлЕуЃЌЫљгаЛљвђЖМЪЧНјЛЏЕФВњЮяЁЃдкВЛЭЌЩњЮяжжжаЃЌОпгаЯрЭЌЙІФмЕФЛљвђЭЈГЃРДдДгкЭЌвЛзцЯШЛљвђЁЃвђДЫЃЌетаЉЛљвђЃЈorthologous genesЃЉБЫДЫНсЙЙЯрЫЦЁЃЯдШЛЃЌБШНЯЙІФмЮДжЊЕФЛљвђКЭDNAЪ§ОнПтжаЙІФмвбжЊЛљвђЕФађСаЯрЫЦадЃЌЮвУЧгаПЩФмдЄВтФГаЉЛљвђЕФЙІФмЁЃ
ЁЁЁЁФПЧАЃЌаэЖрбаОПШЫдБе§дкDNAЪ§ОнПтЕФЛљДЁЩЯПЊЗЂаТЕФDNAаХЯЂПтМАЦфРћгУЯЕЭГЁЃР§ШчЃЌNCBIЕФЭЌдДЛљвђаХЯЂПтCOGЃЈclusters of orthologous groupsЃЉПЩвдЮЊШЫУЧЬсЙЉЯъЯИЕФЭЌдДЛљвђЗжРрКЭЯргІЕФDNAЫГађЬиеїЃЛШеБОЕФЗДгІЭООЖаХЯЂПтKEGGЃЈKyoto encyclopedia of genes and genomesЃЉдђЬсЙЉСЫвЛЬзФмЙЛздЖЏБШНЯКЭдЄВтЛљвђдкЯИАћжаЕФЙІФмЕФЯЕЭГЁЃ
дквРОнDNAвЛМЖНсЙЙдЄВтЛљвђЙІФмЗНУцЃЌDNAЪ§ОнПтЕФзїгУШевцживЊЁЃ